Modèle 1 : Le salaire en fonction de l'ancienneté
Question
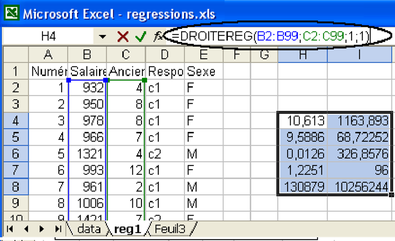
Q1 : Recherche du modèle M1 : y=ax+b
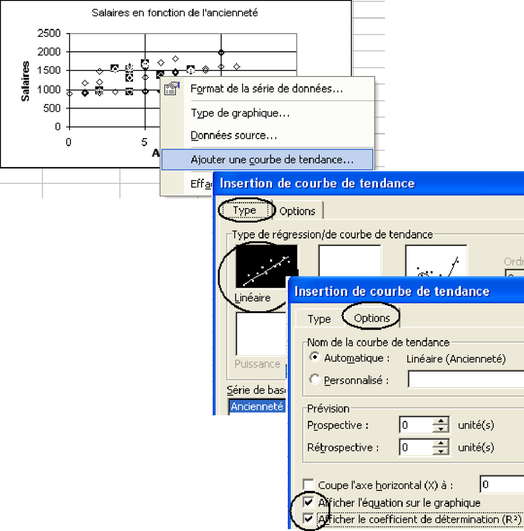
En utilisant la fonction DROITEREG du tableur, trouver les valeurs a et b correspondant à l'équation de régression Salaire = a Ancienneté + b + erreur minimisant les erreurs (voir figure 5.21). Le paramètre b représente le salaire à l'embauche (0 année d'ancienneté) et la valeur de a représente l'augmentation annuelle de salaire, si ce modèle correspond à la réalité, bien sûr.
Question
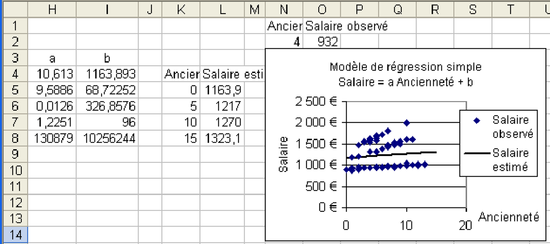
Q2 : Utilisation du modèle M1 trouvé pour les prédictions et la visualisation
Si on remplace l'ancienneté par un nombre quelconque, on a une estimation du salaire correspondant à cette ancienneté selon le modèle. Écrire dans le tableur quelques valeurs d'ancienneté puis calculer le salaire estimé correspondant en utilisant les valeurs de a et de b obtenues (voir colonnes K et L de la figure 5.22). Faire le graphique permettant de comparer valeurs observées et valeurs estimées comme en figure 5.22.
Question
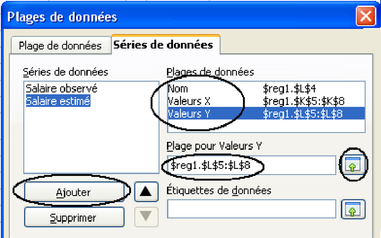
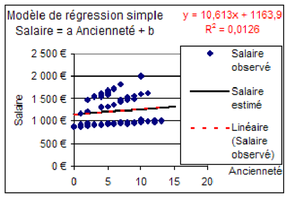
Q3 : Utilisation de l'outil « ajout d'une courbe de régression linéaire » du tableur
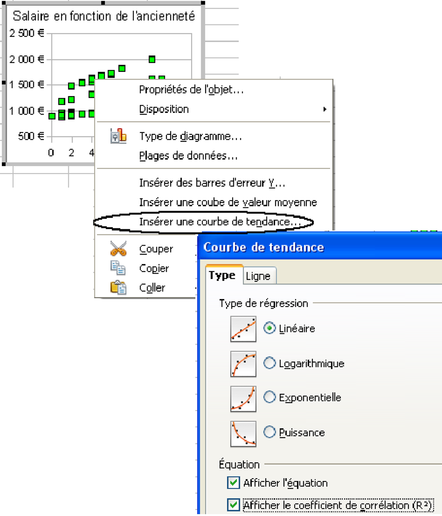
Le tableur permet de dessiner directement les courbes de régression sans faire de calcul. Certains tableurs donnent même l'équation de régression (comme Excel, voir figure 5.23 et OpenOffice3.1). On accède à ces tracés en sélectionnant la série de données, puis en choisissant « Graphique> Ajouter une courbe de tendance » pour Excel et « Insertion>Statistiques » sous OpenOffice. On a alors le choix entre plusieurs courbes de régression. Toutefois cela n'est possible que pour les modèles très simples, comportant une seule variable explicative. Contrôler que la droite que vous avez tracée et la droite de régression dessinée automatiquement par le tableur coïncident, et que l'équation indiquée, ainsi que le coefficient de détermination correspondent bien aux valeurs trouvées avec la fonction DROITEREG.
Question
Q4 : Les résidus au modèle M1
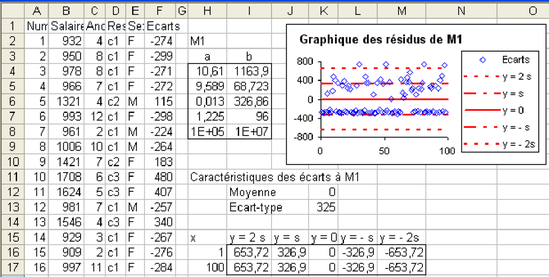
Ajouter une colonne intitulée « écarts » (colonne F de la figure 5.24) contenant pour chaque sujet la différence entre son salaire réel, figurant dans la colonne correspondante, et son salaire estimé d'après l'équation de régression (on utilisera dans la formule, les cellules où figurent a et b, et celles ou figurent x et y). Vérifier qu'on a bien pour moyenne de ces écarts approximativement 0, et pour écart-type, approximativement la valeur figurant dans le tableau à côté de R² (cellules K12 et K13 de la figure 5.24).
Si le modèle est bon, les erreurs suivent une loi normale d'espérance (moyenne) 0, et écart-type s, valeur qui a été rendue par le tableur à côté de R² dans la matrice de résultats. Dans ce cas, on ne doit trouver que 34% des valeurs au maximum à l'extérieur de la bande où y est compris entre –s et s, et au moins 95% des valeurs entre 2s et 2s, le tout étant réparti de façon équilibrée (symétriquement) autour de la droite y=0. Faire un graphique où figurent les points (en utilisant un nuage de points construit sur la seule colonne des écarts) et les droites y=-2s, y=-s, y=0, y=s et y=2s, en insérant des nouvelles données au graphique, ces séries étant situées dans un tableau avec 2 valeurs de x (1 et 100), et pour chacune de ces valeurs, les 5 valeurs de y correspondant aux droites. On doit obtenir le graphique à droite de la figure 5.24.
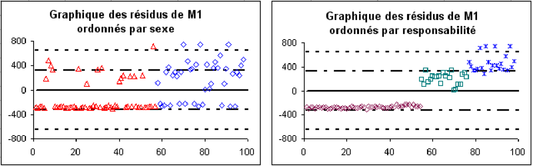
On voit que les conditions de pourcentage paraissent vérifiées (par exemple, on a 4 points dans la première zone à partir du haut, ce qui n'est pas loin des 2,5% attendus), mais pas les conditions de symétrie (au dessus de la droite d'équation y=0, les points s'étalent en hauteur, alors qu'ils sont quasiment alignés sur une droite en dessous de l'axe des x). Pour repérer les individus, trions l'ensemble des colonnes selon le sexe, les femmes se trouvant de la ligne 2 à 58 et des hommes après. On ne voit pas de différences notables entre ces deux parties (figure 5.25 à gauche, F : triangle rouge, M : losange bleu). Faire la même chose en triant selon la responsabilité. On voit (figure 5.25 à gauche, c1 : losange marron, c2 : carré vert, c3 : croix bleue) que pour la responsabilité c1, tous les écarts sont systématiquement négatifs, ce qui signifie que le salaire réel est bien inférieur au salaire estimé, et c'est le contraire pour les 2 autres niveaux de responsabilité. Les conditions de normalité des résidus ne sont plus respectées. On en conclut que le modèle M1 est insuffisant, que la variable « responsabilité » doit intervenir.
")